
pythonは標準入力の方法を変えるだけで大幅に実行速度を改善できます。
特に\(10^5\)以上の入力が発生する場合は、標準入力の高速化は必須になります。
標準入力高速化の準備
標準入力の高速化には準備が必要です。
とりあえず高速化するために次のコードを記述します。
import sys
input = sys.stdin.readlineこの記述がないと高速化されできません。
標準入力の高速化
標準入力のパターンは次の\(8\)パターンだけ覚えてしまえば大丈夫です。
スニペットに登録等しておくと便利です。
標準入力のパターン
- 数値 or 文字列
- \(1\)行に\(1\)つの値 or \(1\)行に複数の値
- \(1\)行 or 複数行
整数
1行に1つの値
n = int(input().rstrip('\n'))1行に複数の値
n = list(map(int, input().rstrip('\n').split()))1行に1つの値が複数行
n = [int(input().rstrip('\n')) for _ in range()]1行に複数の値が複数行
n = [list(map(int, input().rstrip('\n').split())) for _ in range()]文字列
1行に1つの値
s = str(input().rstrip('\n'))1行に複数の値
s = list(map(str, str(input().rstrip('\n')).split()))1行に1つの値が複数行
s = [str(input().rstrip('\n')) for _ in range()]1行に複数の値が複数行
s = [list(map(int, input().rstrip('\n').split())) for _ in range()]実行速度の比較のためのデータ作成
実際にどの程度の実行時間の差があるのか、AtCoderのコードテスト上で比較してみます。
\(1\)行に\(1\)の値のパターンは(読込データ量が少なすぎて)実行時間に差が出ないので省略します。
まずは読込対象のデータを作成します。
1行に複数の値
\(1\)行に複数の値があるデータを作成します。
import os
f = open(os.path.dirname(os.path.abspath(__file__)) + "/input.txt", 'w')
for i in range(10 ** 6):
f.write(" " + str(1))
f.close()
出力されるファイルは次のようになっています。
1 1 1 1 1 ・・・・・・ 11行に1つの値が複数行
\(1\)行に\(1\)つの値が複数行のデータを作成します。
import os
f = open(os.path.dirname(os.path.abspath(__file__)) + "/input.txt", 'w')
for i in range(10 ** 6):
f.write("\n" + str(1))
f.close()
出力されるファイルは次のようになっています。
1
1
1
1
・
・
・
11行に複数の値が複数行
\(1\)行に複数の値が複数行のデータを作成します。
import os
f = open(os.path.dirname(os.path.abspath(__file__)) + "/input.txt", 'w')
for i in range(10 ** 6):
if i % 1000 == 0:
f.write("\n" + str(1) + " ")
else:
f.write(str(1) + " ")
f.close()
出力されるファイルは次のようになっています。
1 1 1 1 1 ・・・・・・ 1
1 1 1 1 1 ・・・・・・ 1
1 1 1 1 1 ・・・・・・ 1
1 1 1 1 1 ・・・・・・ 1
・
・
・
1 1 1 1 1 ・・・・・・ 1実行速度の比較
入力データ数ははAtCoderのABCレベルの上限の\(10^6\)で比較しています。
【整数】1行に複数の値を
標準
def solve():
n = list(map(int, input().split()))
if __name__ == '__main__':
solve()
python

pypy
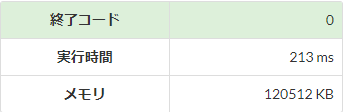
高速化
import sys
def solve():
input = sys.stdin.readline
n = list(map(int, input().rstrip('\n').split()))
if __name__ == '__main__':
solve()
python

pypy

【整数】1行に1つの値が複数行
標準
def solve():
n = [int(input()) for _ in range(10 ** 6)]
if __name__ == '__main__':
solve()
python

pypy
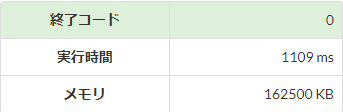
高速化
import sys
def solve():
input = sys.stdin.readline
n = [int(input().rstrip('\n')) for _ in range(10 ** 6)]
if __name__ == '__main__':
solve()
python

pypy

【整数】1行に複数の値が複数行
標準
def solve():
n = [list(map(int, input().split()))for _ in range(1000)]
if __name__ == '__main__':
solve()
python

pypy

高速化
import sys
def solve():
input = sys.stdin.readline
n = [list(map(int, input().rstrip('\n').split()))for _ in range(1000)]
if __name__ == '__main__':
solve()
python

pypy

【文字列】1行に複数の値を
標準
def solve():
s = list(map(str, input().split()))
if __name__ == '__main__':
solve()
python

pypy
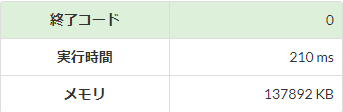
高速化
import sys
def solve():
input = sys.stdin.readline
s = list(map(str, input().rstrip('\n').split()))
if __name__ == '__main__':
solve()
python

pypy
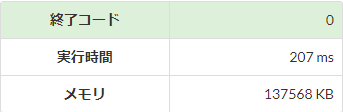
【文字列】1行に1つの値が複数行
標準
def solve():
s = [str(input()) for _ in range(10 ** 6)]
if __name__ == '__main__':
solve()
python

pypy

高速化
import sys
def solve():
input = sys.stdin.readline
s = [str(input().rstrip('\n')) for _ in range(10 ** 6)]
if __name__ == '__main__':
solve()
python

pypy
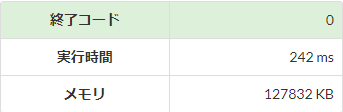
【文字列】1行に複数の値が複数行
標準
def solve():
s = [list(map(str, input().split()))for _ in range(1000)]
if __name__ == '__main__':
solve()
python

pypy

高速化
import sys
def solve():
input = sys.stdin.readline
s = [list(map(str, input().rstrip('\n').split()))for _ in range(1000)]
if __name__ == '__main__':
solve()
python

pypy

実行速度比較まとめ
標準入力の高速化を実際にAtCoderの環境で比較してみると、入力行数が多くなるほど高速化の効果が大きくなり、その効果は\(5\)倍程度となっています。
それ以外に関しては誤差の範囲で、pythonとpypyでも明確な差は出ませんでした。
入力行数が多い問題でTLEしてしまう場合には高速化を試してみてください。